
Artificial Intelligence
Deep dive into AI with hands-on practice

Artificial intelligence isn’t just a trend — it’s a new way of building software and providing value. Understanding AI fundamentals can elevate your strategic insight and open up a world of innovative product possibilities.
This quick guide will help get you up to speed and start building your skills with hands-on practice.
What Does AI Do?
At its core, AI is about making predictions.
There are two types of predictions: regression and classification.
Regression is used to guess a value in a continuous range, like predicting the sale price of a home.
Classification is used when you want to sort something into a category. For example, if something is a hot dog (or not).

Classification and regression problems can be solved by various AI models, with different levels of accuracy and complexity. Some models can be used for either classification, regression, or both.
Another key idea in AI is deterministic and non-deterministic systems. Most software we build today is deterministic — it follows clear if-this-then-that logic. Word processors, email clients, web browsers, and social media are all deterministic applications. They are extremely good at reliably completing the same tasks that can be fully described by if-this-then-that statements.
Non-deterministic systems are applications that don’t follow strict rules. These systems are able to learn about the relationships over time instead of relying on explicitly stated rules.
Deterministic Models
Although most AI models are non-deterministic, there are a few basic deterministic models available. It’s a good idea to use simple models to benchmark performance for more complex models.
Linear Regression
If you took any mathematics course in college, you’re likely familiar with linear regression. This is a simple mathematical formula that can be used to predict a value on a continuous range.
Let’s try it out on the following data:

When we plot this data, we get the following:

A linear regression model generates a straight line that best fits the data by minimizing the total distance between itself and each point in the data set. This line can then be used to predict values that are not present in the original data set.

When we run our model to predict the value of a 5-bedroom home, it returns $913,124. Looks like our model is working!
Linear regression works well for small- to medium-size data sets with clear, linear relationships between attributes. It is also easy to interpret, making it a great choice for any prediction that needs to be explained later.
Want to try for yourself? Check out the code here.
Decision Trees
Decision trees capture a sequence of decisions in a specific order. They are commonly used for classification problems but can also be used for regression.
Let’s say we had the following data on dog breeds:

We could build a decision tree to predict dog breeds based on their size and energy level. The tree would look something like this:

When we ask for a small dog with low energy, we always get a shih tzu.
Both the training and prediction of decision trees is deterministic — we always end up with the same decision points when training with the same data set.
What Is Training?
AI models train by making many attempts at solving the same problem. Once all of the training time is used, the model settles on the best configuration it found.
A popular way to train models is with supervised learning. This is an approach where we give the model the correct answer so that it can evaluate the difference between its prediction and reality. In the case of our home sales example, we would provide the real sale price with the number of bedrooms.

The goal is to minimize the difference between the model’s predictions and real values, without getting so specific that the model only works on our example data. A model that is too specific to its training data is overfitting.
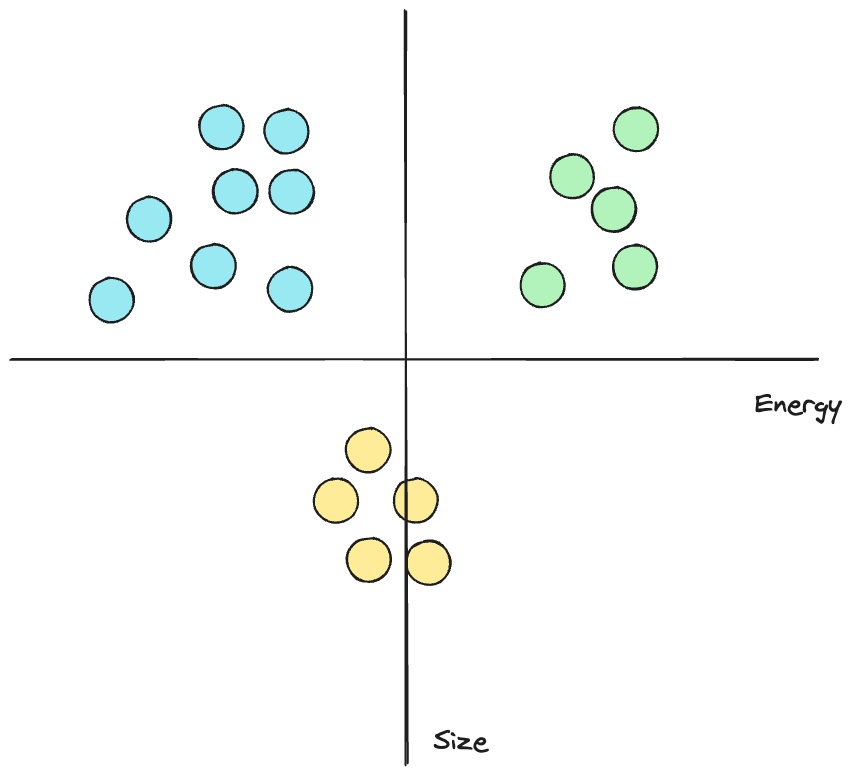
Another way to train a model is unsupervised learning. We do not provide the correct answer to the model but instead allow the model to find relationships. For example, we could use unsupervised learning to group together different types of dog breeds based on data such as size and energy levels.
This would not return a specific breed — it would tell us which dogs are similar and how many groups of dogs exist.
Non-Deterministic Models
Non-deterministic models add an element of randomness to their training or responses. They are typically more difficult to interpret, but they excel at capturing relationships in data without the rules being explicitly stated.
Let’s take a look at two models as an example: random forest and neural networks.
Random Forest
Random forest is a model that adds a non-deterministic element to the decision tree. Instead of having only one tree, we have a lot of trees. Each tree will use different decision points as it trains on the underlying data.
Let’s extend our dog breed example to include a few more data elements:

Our random forest model can use all of these data elements to build multiple decision trees. Each tree is different and votes on dog breeds based on their size, energy level, weight, and height.

It’s common to see not just two, but upward of 64 different tree configurations for a single data set. The decision points selected for each tree are non-deterministic — meaning you would get different trees each time you trained the model. Once trained, the trees do not change.
Random forests are much better models than decision trees because they can handle more variation in the underlying data. Put another way, they are less likely to overfit.
Neural Networks
Neural networks are the underlying model for many recent advancements in AI, from ChatGPT to image recognition. They work by forming a series of decision points that mimics the human brain. Neural networks are a series of interconnected nodes that pass data from the front to the back.
A neural network trained on our housing data might look like this:
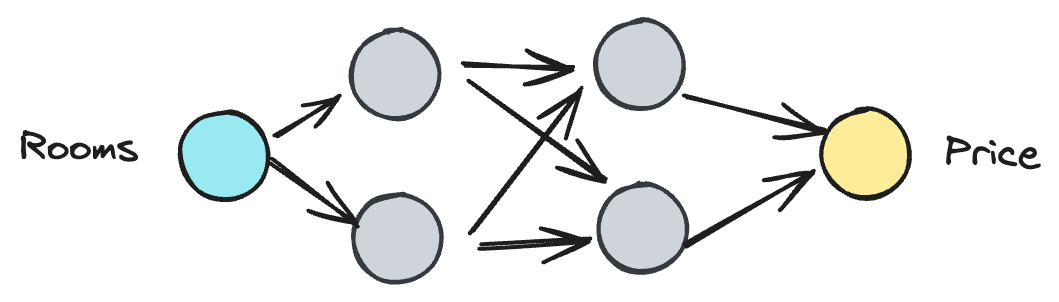
The front is called the input layer. There’s one node for each input variable (like rooms).
The end is called the output layer. For regression problems, there’s one node. For classification, there is one for each option.
The middle is called the hidden layer. This is where the model transforms the input data to arrive at a prediction.
Creating a neural network sounds hard, but it’s really just a few lines of code. Most of the effort is spent collecting, preparing, and analyzing the underlying data. For our model, I used a more robust housing data set, with 550 records and attributes like bathrooms, square footage, and guest rooms.
Here’s what it looks like when the neural network is training:

You can see that we started with a larger gap between the predicted and actual values, but the model learned quickly. It then made incremental progress without any major improvements before ending on the 50th iteration.
So is our model good? Not really. Neural networks typically require more data and training time to become effective. For a 5,750-square-foot home with 3 bedrooms and 2 baths, the model predicted a price of $5,476,431. Dropping that down to 1,200 square feet, we have a more modestly priced prediction at $3,526,332.
Want to try for yourself? Check out the code here.
Generative AI
The models we described above are classic machine-learning techniques that have been around for decades. Since the late 2000s, machine learning has gone through multiple evolutions.
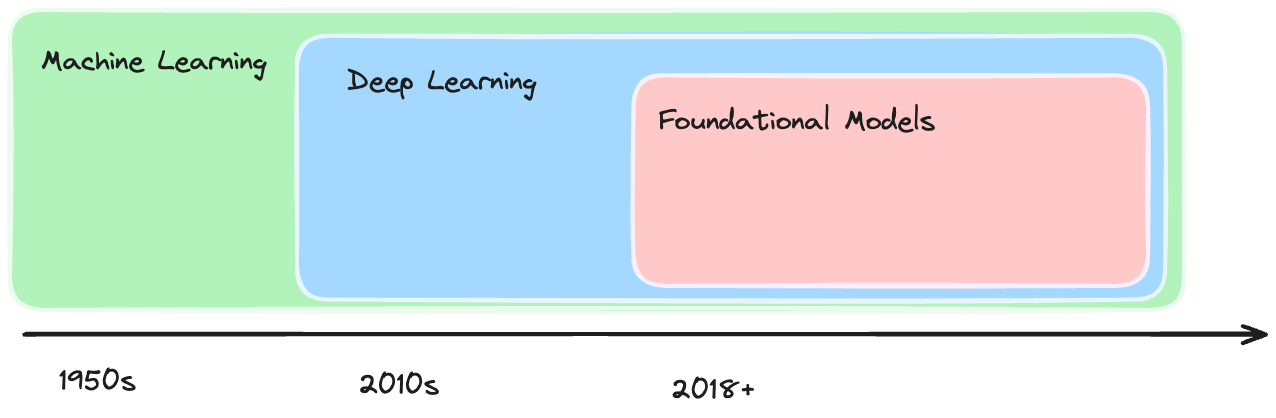
Image credit: Nvidia
The first major shift was deep learning, where neural networks would be trained with many more layers than prior approaches (50 to 1,000+). Deep learning led to advancements in image recognition, speech recognition, fraud analysis, and more.
More recently, transformers and foundational models have led to tools like ChatGPT and DALL-E. Although these models are still based on neural networks, they have many additional components that allow the model to better understand context. When combined with training on terabytes of data from the internet, we get general-purpose AI tools like ChatGPT.
Foundational Models and Fine-Tuning
Foundational models are massive models trained on terabytes of data and requiring petabytes of compute. Each training run can cost millions of dollars. When training is complete, you get a general-purpose model with many capabilities: from translating text and writing blog posts to understanding financial statements and providing recommendations. Both the training process and model outputs are non-deterministic.
Foundational models also differ in their approach to training. These models are largely unsupervised and can be trained on multiple computers at the same time. This greatly reduces the effort required to train the model and allows developers to reduce the total training time.
The specifics of what data is used and how much is labeled is closely held information by companies building foundational models.
Here’s a clip of Sam Altman talking about OpenAI’s training techniques for Sora, a generative AI model for video.
Full interview: Sam Altman: OpenAI, GPT-5, Sora, Board Saga, Elon Musk, Ilya, Power & AGI | Lex Fridman Podcast #419
If it costs millions of dollars in compute, highly skilled talent, refined human input, and access to terabytes of well-formed data to produce these models, it’s obvious that not all companies will want to build from scratch. Fortunately, these models support fine-tuning. This is a process where additional data is provided to the model after the generalized training is complete. Combined with well-made prompts, a fine-tuned foundational model can return high-quality responses based on your specific data.
Foundational models are built by companies such as:
Meta — Llama 2
Amazon — Titan
OpenAI — GPT4
Google — PaLM2
Cohere — Command R+
How Can I Practice?
There are three ways you can start using generative AI:
Download a trained open-source model, like Llama 2, and run it on your computer
Make an API request to a hosted model, like GPT-4
Use a consumer product that leverages AI, like Sana AI
Want to build your very own LinkedIn post generator? Check out this video for a 10-minute guide.
In the Wild: Loom
Loom is a video sharing and screen recording platform. It helps professionals save time by sending quick videos instead of booking meetings and facilitates collaboration through comments, reactions, and more.
Loom has adopted AI as a core component of their product offering. From writing your video title and description to detecting and removing silences automatically, Loom uses AI to streamline the end-user experience of creating and sharing videos.
But they’re not done yet. Loom has plans to push their AI offering even further, with features like auto-creating Jira tickets and drafting code documentation.

Loom’s AI features: https://www.loom.com/ai
Would you ever use a screen recording to report a Jira issue? Or would you rather share your OKR updates with personalized introductions for each attendee?
Putting It All Together
Understanding how AI is built will help you make better build vs. buy decisions, frame solutions that can be solved with non-deterministic approaches, and better assess how you can deliver customer value using foundational models and generative AI.