
A Guide to Building Data-Driven Products
Building blocks of modern data products

Hey, I’m Colin! I help PMs and business leaders improve their technical skills through real-world case studies. For more, check out my Live cohort course and subscribe on Substack.
If you've spent any time in tech, you've probably heard the phrase "data is the new oil." While that might be overused, there's truth to it - companies are increasingly building entire products around data itself. Whether you're working at a big tech company or a small startup, chances are you'll encounter data products in your career as a PM.
Let’s dive into the 4 types of data products, how to build one, and the skills you need to be a good data PM.
What is a data-driven product?
A data-driven product is one that provides value through raw data, analysis, or exchange. This can be a unique curation of data, algorithms that provide unique insight, or exchange platforms that make it easy to transact data.
One interesting pattern of data products is that they often build on top of one another. Each product in the stack provides a further layer of cleaning, analysis, or accessibility.
Below, I’ve outlined 4 types of data products:
Raw Data Access
Data Exchange Platforms
Analytics & Insights
Analysis Tools

Raw Data Access
Companies like Plaid and LexisNexis provide access to raw data that’s been cleaned and standardized. Rather than attempting to source, clean, and maintain data yourself, partnering with data providers gives you a fast way to provide value-add services on top of raw data. Data can be accessed via API or file transfers with SFTP.
Analytics & Insights
Analytics and insight products take raw data and derive meaning from it. For example, a Social Determinants of Health product takes in lifestyle, economic, and demographic data to predict a patient’s ability to access care or their risk of future adverse events. Another popular example is Palantir, who provides insights across multiple different industries. Analytics & insight products can also be internally facing, such as recommendation or machine learning systems.
Data Exchange
Some of the most interesting companies in tech facilitate data sharing between organizations. For example, LiveRamp helps companies resolve identity across platforms and Datavant enables healthcare data exchange while maintaining privacy. These products solve complex technical and business problems around data sharing by providing a unique id that can be joined across multiple datasets. Customers can then connect their data across a wide variety of sources without having to solve entity resolution issues every time.
Analytics Tools
Finally, we have products that help companies understand their own data better. Think Amplitude, Mixpanel, or even internal analytics dashboards. These tools need to handle massive scale while remaining intuitive enough for non-technical users. Analytics tools are not true ‘data products’, but require similar expertise from Product Managers.
How to build a data product
Working on a data product requires thinking about some unique challenges. Let's break down the key components of a data product:

Ingestion
Data ingestion is the process of intaking data from various sources and formats, and standardizing into a single data model. Data can flow in from APIs or file transfer, and can be in batches or streamed in continuously.
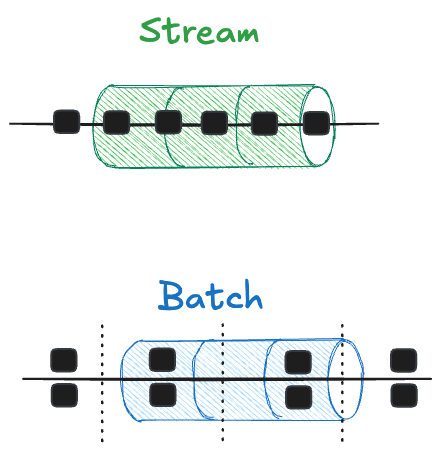
Batching is used to process data in groups or chunks. Rather than processing each data element individually, they will be grouped together in groups or batches. Each batch is processed as a single unit. Batching improves reliability but slows down the overall pipeline speed.
Streaming is used to process each data element independently. Data flows continuously from its source to the ingestion system, where it is then transformed into a standard data model. Streaming allows for near real-time updates, but requires highly scalable systems that can accept a massive number of requests in a short period of time.
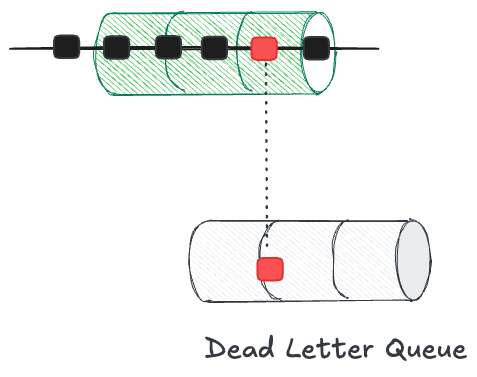
Unfortunately, not all data that arrives will flow nicely through your pipelines. You’ll need to handle malformed requests and make decisions on which issues can be ignored and which should trigger alerts.
One strategy for handling ingestion issues is a dead-letter queue. When the initial request fails to flow through the standard pipeline, the request is dropped from the queue into the dead-letter queue. This request can be inspected and potentially retriggered at a later date.
Two key considerations of ingestion are consistency and throughput. Usually there is an inverse relationship between these – if you need 100% of events to be ingested correctly, the speed at which you can ingest data will slow greatly. If you have lax requirements for consistency, you can ingest all events as they appear. Handling these tradeoffs is a key consideration of any data ingestion system.

These data systems typically store data in data lakes or warehouses with products like Snowflake, BigQuery, or Databricks.
Analysis
Once data is ingested and stored, you typically want to apply some analytics to it.
There are two patterns of data transformation used before performing analysis: ETL and ELT.
